
Die Werbeindustrie unterscheidet sich von anderen Branchen in vielerlei Hinsicht. Betrug ist keine davon. Denn Betrüger tummeln sich überall. Auch Digital Advertising wird davon nicht verschont. In diesem Artikel stellen wir einige Ansätze zur Bekämpfung von Fraud vor. Um zu erklären, wie Betrüger mit gefälschten Werbeanzeigen Geld verdienen, müssen wir zunächst aber die Mittelflüsse in der digitalen Werbeindustrie verstehen. Der Einfachheit halber sei hier ein Szenario mit nur vier Akteuren gewählt. Im Tagesgeschäft partizipieren neben diesen noch weitere Parteien.
Die Werbetreibenden
Werbetreibende kaufen Präsenz in Apps und Websites. Durch diese Investitionen fliessen Werbebudgets in die Industrie. Die entsprechenden Werbekampagnen verfolgen unterschiedliche Ziele und KPI’s, wie eine maximale Netto-Reichweite, eine hohe Klickrate oder möglichst viele Sales-Conversions.
Um Streuverluste zu verhindern, werden Kampagnen innerhalb abgesteckter Zielgruppen ausgesteuert. Diese weisen das grösste Interesse auf an den beworbenen Produkten oder Dienstleistungen. Fraud gehört hier nicht dazu. Denn der Einkauf künstlicher, von Betrügern generierten Ad Impressions wird zu keinen Konvertierungen führen.
DSP’s
Demand-Side Platforms steuern Kampagnen automatisiert im Auftrag des Werbetreibenden aus. Dazu selektieren DSP’s auf Basis von Datenpunkten wie Standort, Geschlecht oder Alter spezifische Zielgruppenkontakte und geben für deren Einkauf Gebote in Echtzeit ab (Real Time Bidding). Fraud soll dabei nicht eingekauft werden. Würden Advertiser erkennen, dass ihre Werbebudgets in Fraud investiert werden, wären sie nicht glücklich und würden die Zusammenarbeit mit dem Betreiber der entsprechenden DSP wohl einstellen.
Exchanges
Hier wird das von Publishern bereitgestellte Inventar verkauft. Je mehr Ad Impressions einer Exchange zur Verfügung stehen, desto höhere Umsätze können mit dem Verkauf des entsprechenden Inventars erzielt werden. Das Hauptinteresse von Exchanges besteht also darin, möglichst viel Inventar anbieten und verkaufen zu können.
Publisher
Als Schnittstelle zu den Konsumenten stellen Publisher die für Werbemittelsichtkontakte nötigen Werbeträger bereit. Für jede generierte Ad Impression werden die Publisher mit einem Teil des von den Werbetreibenden investierten Geldes vergütet (abzüglich Margen von DSP’s und Exchanges). Über je mehr User die Publisher verfügen, desto mehr Ad Impressions können sie verkaufen. Die meisten Publisher versuchen, möglichst viele Besucher anzuziehen, indem sie Inhalte von hoher Qualität anbieten, beispielsweise News oder Video-Tutorials. Einige Publisher bevorzugen es aber, ihren Traffic künstlich zu vergrössern, um ihre Einnahmen zu steigern. Üblicherweise werden Betrüger von Publishern beauftragt, die Reichweite ihrer Websites durch Anreicherung mit Fake-Traffic zu erhöhen. Dieser Traffic Fraud soll von organischem Traffic möglichst nicht unterschieden werden können.
Strategien für Fraud Detection
Die Bekämpfung von Fraud wird ein nie endender Kampf bleiben, dem wir uns täglich stellen müssen. Denn ähnlich wie beim Sport-Doping werden Betrüger immer versuchen, neue Wege zu finden, um Werbetreibende zu hintergehen. Als Treuhänder von Werbegeldern müssen wir deshalb wach bleiben um jeden Tag aufs Neue bisher unbekannte Betrugsversuche zu identifizieren. Da es kaum möglich ist, einen repräsentativen Ground Truth-Datensatz zu bekommen, wird hauptsächlich mit Unsupervised Learning-Methoden gearbeitet. Im Folgenden zeigen wir einige solcher Methoden der Fraud Detection, die im Markt angewendet werden.
Site Entropy
Im Kontext von Advertising Fraud wird oft ein exemplarisches Ereignis als den Besuch einer bestimmten Website von einer bestimmten Entität definiert, beispielsweise einer IP-Adresse. Wenn dieses Ereignis unnatürlich häufig eintritt, ist zu vermuten, dass hinter der entsprechenden IP-Adresse ein begründeter Verdacht steht. Deshalb wird der eingehende Traffic fortlaufend analysiert und es wird ein Entropie-Koeffizienten für jeden Publisher berechnet. Publisher, welche zum Beispiel immer vom selben Satz an IPs besucht werden, erhalten einen niedriegen Entropie-Koeffizienten, während Seiten, die von vielen verschiedenen IPs besucht werden, ein hoher Entropie-Koeffizient zugeordnet wird. Seiten mit tiefem Entropie-Koeffizienten werden als verdächtig eingestuft und geblacklisted. Weitere Informationen zu Entropie-basierter Methodologie zur Detektion von Digital Advertising Fraud finden sich im Paper von Pastor Valles.
Massive Low Intensity Attack
Diese Form unnatürlicher Besucherfrequenz wird über eine breite Masse von IPs oder Devices getätigt, jedoch in geringer Intensität. Konkret können dies spezifische IPs sein, welche eine Website einmal pro Tag besuchen, dies aber jeden einzelnen Tag im Jahr. Handelt es sich dabei um ein reichweitenstarkes Newsportal oder Social Network, kann das legitim sein. Tritt ein solches Phänomen jedoch auf weniger populären Websites auf, handelt es sich möglicherweise um Betrug.
Click Patterns
Click Bots werden in unterschiedlichen Komplexitäten programmiert und eingesetzt. Sie können beispielsweise erkannt werden, wenn sie den Klick immer an der exakt selben Position eines Werbemittels auslösen. Ein weiteres Indiz kann der zeitliche Abstand zwischen dem Rendering der Ad Unit und dem Klick sein. Zeigen sich hier verdächtige, abnorme Häufungen, kann dahinter ein Bot stehen.
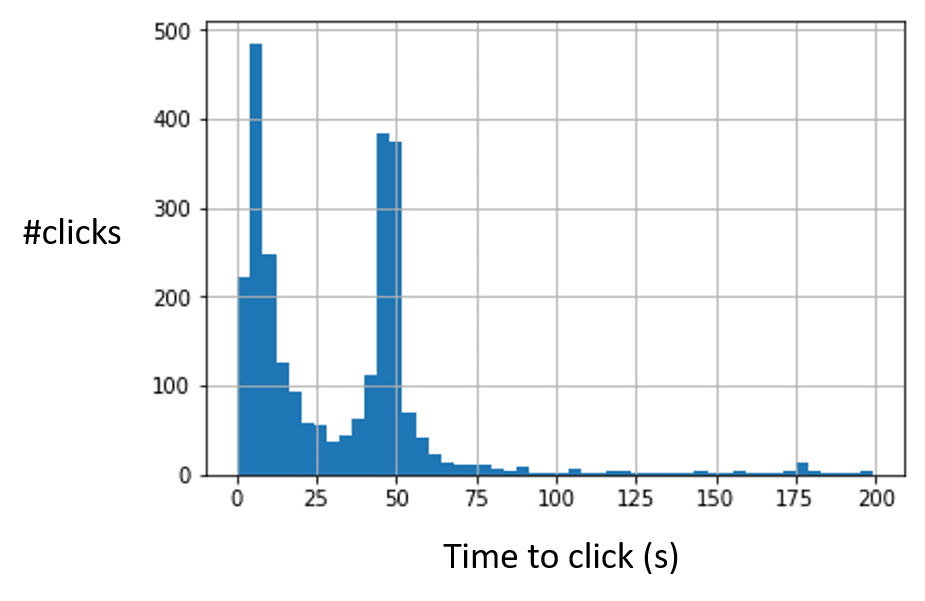
Turing Tests
Mit den Massnahmen zur Fraud Prevention wurde im Markt im Grunde genommen eine sehr spezifische Version des Turing Tests entwickelt. Im klassischen Turing Test gibt sich eine Maschine als Mensch aus. Eine Testperson soll nun entschieden, ob es sich dabei wirklich um einen Menschen oder doch um eine Maschine handelt. Je besser Maschinen in der Lage sein werden, menschliches Verhalten nachzuahmen, desto stärker werden die Anforderungen an zuverlässige Fraud Detection wachsen.
Ein Vorteil wird uns dabei aber immer bleiben. Denn Bots müssen nicht nur in der Lage sein, uns Menschen zu betrügen, sie müssen auch andere Maschinen hinters Licht führen können. Unserer Erfahrung nach kann dies durchaus anspruchsvoller sein. Denn mit Maschinen können wir wiederum auf die Methoden von Machine Learning und Künstlicher Intelligenz zurückgreifen.
White- und Blacklisting
Data Science ist jedoch nicht die einzige Disziplin mit dem Ziel, den ausschliesslichen Einkauf von Traffic höchster Qualität sicherzustellen. So werden ergänzend auch stetig aktualisierte Whitelists von Websites und Apps eingesetzt, um Brand Safety zu jedem Zeitpunkt garantieren zu können. Dasselbe gilt auch für Blacklists, wo sich beispielsweise Dummy-Sites oder Apps wiederfinden, welche nur darauf abzielen, Werbung zu verkaufen, ohne sinnvolle Inhalte anzubieten.
Der Kampf wird weitergehen
Heute kann niemand genau quantifizieren, wie viele Betrüger tatsächlich gefälschtes Inventar produzieren oder künstliche Interaktionen tätigen. Advertising Fraud wurde aber von der gesamten Branche als wachsendes Problem erkannt, welches wir aus allen möglichen Perspektiven angehen und bekämpfen müssen. Dank modernen Technologien existiert heute eine Vielzahl wirksamer Methoden, um Advertising Fraud zuverlässig aufzuspüren und zu eliminieren. Denn nur mit echtem Inventar kann eine Kampagne die gewünschte Werbewirkung entfachen, welche wiederum durch Messung definierter KPI’s überprüft und vom Advertiser jederzeit bewertet werden kann.
Autor: Ignacio Traverso Ribon,
Data Scientist bei Adello, IAB-Firmenmitglied